Künstliche Intelligenz (KI) umfasst Technologien, die es Maschinen ermöglichen, aus Erfahrungen zu lernen, sich an neue Eingaben anzupassen und menschenähnliche Aufgaben auszuführen. Dazu zählen insbesondere Problemlösung, Mustererkennung und Entscheidungsfindung.[1] [3]
Der Begriff „Artificial Intelligence“ wurde 1956 von John McCarthy auf der Dartmouth Conference geprägt, die als Startpunkt moderner KI-Forschung gilt [1]. Heute ist KI ein Schlüsselhebel der digitalen Transformation und das auch in der Landwirtschaft. Sie ermöglicht unter anderem:
Allerdings hängt die Leistungsfähigkeit solcher Systeme stark von den verfügbaren Daten und Einsatzbedingungen ab. Studien zur automatischen Pflanzenkrankheitserkennung zeigen beispielsweise, dass Deep-Learning-Modelle auf standardisierten Datensätzen mit gleichmäßigem Hintergrund sehr hohe Genauigkeiten erreichen können, ihre Leistung bei realen Feldbildern mit wechselnden Lichtverhältnissen und komplexen Hintergründen jedoch deutlich abnimmt [13] [14]. Dies verdeutlicht, dass KI-Anwendungen häufig unter kontrollierten Bedingungen entwickelt werden und ihre Übertragbarkeit auf reale landwirtschaftliche Praxis sorgfältig geprüft werden muss.
Unter KI versteht man die maschinelle Nachbildung kognitiver Fähigkeiten des Menschen. In der Literatur wird häufig zwischen „starker KI“ (allgemeine, menschenähnliche Intelligenz) und „schwacher KI“ (spezialisierte Verfahren, z. B. Maschinelles Lernen) unterschieden. In der Praxis dominieren derzeit schwache-KI-Verfahren. [2]
Die KI lässt sich in mehrere Teilbereiche unterteilen, die umgangssprachlich oft synonym verwendet werden. [1] [2]
Dabei ist zu beachten, dass nicht alle genannten Bereiche strikt als Teilbereiche der KI gelten. Insbesondere die Robotik stellt ein eigenes technisches Forschungsfeld dar, das jedoch häufig KI-Methoden nutzt, um autonome oder intelligente Systeme zu entwickeln.
Maschinelles Lernen (ML) ist ein zentraler Teilbereich der künstlichen Intelligenz. Im Gegensatz zur klassischen Programmierung, bei der jeder Entscheidungsschritt explizit vorgegeben wird, lernen ML-Systeme aus Beispieldaten. Während ein traditionelles Computerprogramm festen Regeln folgt („Wenn A, dann B“), erkennt ein ML-Modell selbstständig Muster in großen Datenmengen. Auf Basis dieser Muster kann es Vorhersagen treffen oder Entscheidungen unterstützen. [4]
Je nach Problemstellung kommen unterschiedliche Lernmethoden zum Einsatz:
Überwachtes Lernen (Supervised Learning)
Das System lernt mit bereits bekannten Lösungen („gelabelten Daten“).
Beispielsweise werden Bilder von gesunden und kranken Pflanzen mit der jeweiligen Kategorie beschriftet. Das Modell lernt, diese Unterschiede zu erkennen und kann später neue Bilder selbstständig einordnen.
Unüberwachtes Lernen (Unsupervised Learning)
Hier erhält das System keine vorgegebenen Zielwerte. Es erkennt eigenständig Muster oder Gruppierungen in den Daten. Ein Beispiel ist die Analyse von Sensordaten aus der Tierhaltung: Dabei können Daten zu Bewegung, Aktivität oder Fressverhalten von Kühen ausgewertet werden, sodass das System automatisch unterschiedliche Verhaltensmuster wie Ruhephasen, Fresszeiten oder ungewöhnliche Aktivität erkennt.
Teilüberwachtes Lernen (Semi-Supervised Learning)
Diese Methode kombiniert gelabelte und ungelabelte Daten. Sie wird eingesetzt, wenn nur wenige beschriftete Trainingsdaten verfügbar sind, da deren Erstellung häufig zeit- und kostenintensiv ist. Ein Beispiel ist die Bildanalyse zur Unkrauterkennung: Nur ein Teil der Pflanzenbilder wird manuell als „Kulturpflanze“ oder „Unkraut“ gekennzeichnet, während das Modell zusätzlich eine große Menge unbeschrifteter Bilder nutzt, um seine Mustererkennung zu verbessern.
Verstärkendes Lernen (Reinforcement Learning)
Das Modell lernt durch ein Belohnungssystem. Es probiert verschiedene Handlungen aus und wird für erfolgreiche Strategien „belohnt“. Diese Methode wird beispielsweise bei autonomen Robotern eingesetzt, die optimale Bewegungsabläufe erlernen.
Im Gegensatz zur klassischen Softwareprogrammierung werden Modelle des Maschinellen Lernens nicht durch fest vorgegebene Regeln erstellt, sondern mithilfe von Trainingsdaten „angelernt“. Dieser Prozess wird als Trainingsphase bezeichnet. Während des Trainings analysiert das Modell viele Beispieldaten und passt interne Parameter so an, dass die Vorhersagen möglichst korrekt sind. Anschließend folgt eine Validierungsphase, in der überprüft wird, wie gut das Modell mit neuen, bisher unbekannten Daten arbeitet. Erst danach wird es in ein Softwaresystem integriert und produktiv eingesetzt. Obwohl die Trainingsphase häufig rechenintensiv und zeitaufwendig ist, sind die fertigen Modelle in der Anwendung meist sehr effizient. Dadurch können ML-Modelle auch auf mobilen Geräten, in Apps oder in eingebetteten Systemen (z. B. Sensoren oder Landmaschinen) eingesetzt werden.
Eine zentrale Voraussetzung für Maschinelles Lernen sind ausreichend große Datenmengen. Für klassische ML-Verfahren werden pro relevantem Merkmal in der Regel mindestens 50 bis 100 Datensätze benötigt, sofern die entscheidenden Eigenschaften der Daten bereits bekannt oder technisch extrahierbar sind. [4]
Neuronale Netze sind spezielle Modelle des Maschinellen Lernens und funktionieren ähnlich wie das menschliche Gehirn. [5][2]Sie bestehen aus vielen miteinander verbundenen „künstlichen Neuronen“, die Informationen verarbeiten und weiterleiten.
Ein neuronales Netz ist in mehrere Schichten aufgebaut (siehe Abbildung):
Jede Verbindung zwischen den Neuronen besitzt ein sogenanntes Gewicht. Diese Gewichte bestimmen, wie stark ein Signal weitergegeben wird. Während des Trainings werden diese Gewichte schrittweise angepasst, sodass das Netz immer bessere Vorhersagen trifft. Je mehr verborgene Schichten ein Modell besitzt, desto komplexere Zusammenhänge kann es erkennen. Einfache Netze mit wenigen Schichten werden als flache neuronale Netze bezeichnet. Modelle mit vielen Schichten bilden die Grundlage des sogenannten Deep Learning. Neuronale Netze werden besonders dann eingesetzt, wenn sehr komplexe Muster erkannt werden müssen – beispielsweise bei der Bildanalyse, Sprachverarbeitung oder der Auswertung großer Sensordatenmengen in der Landwirtschaft. [2]
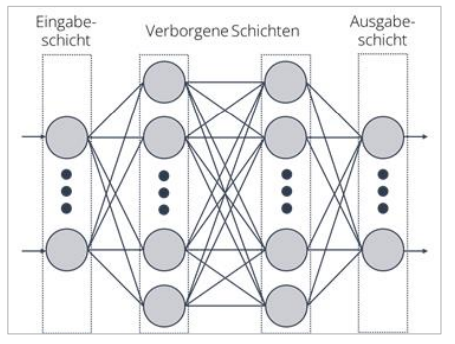
Deep Learning ist eine spezielle Form des Maschinellen Lernens, die auf tiefen neuronalen Netzen basiert. „Tief“ bedeutet in diesem Zusammenhang, dass das Modell aus vielen aufeinanderfolgenden verborgenen Schichten besteht. Während einfache neuronale Netze nur wenige Schichten besitzen, enthalten Deep-Learning-Modelle oft Dutzende oder sogar Hunderte Verarbeitungsebenen. Dadurch können sie sehr komplexe Muster in großen Datenmengen erkennen. Deep Learning ist somit keine eigenständige Kategorie der Künstlichen Intelligenz, sondern eine Weiterentwicklung neuronaler Netze innerhalb des Maschinellen Lernens. Ein entscheidender Unterschied zu klassischen ML-Verfahren besteht darin, dass Deep-Learning-Modelle relevante Merkmale selbstständig aus Rohdaten ableiten. Während bei traditionellen Verfahren wichtige Eigenschaften (z. B. Pflanzenhöhe oder Blattfarbe) häufig manuell definiert werden müssen, lernt ein Deep-Learning-Modell diese Merkmale eigenständig aus Bildern, Sensordaten oder Texten.
Diese Fähigkeit macht Deep Learning besonders leistungsfähig in Bereichen wie:
Allerdings geht die hohe Leistungsfähigkeit mit einem deutlich höheren Bedarf an Trainingsdaten und Rechenleistung einher. Deep-Learning-Modelle benötigen meist sehr große Datenmengen, um zuverlässige Ergebnisse zu liefern. [4] In der Landwirtschaft bildet Deep Learning die Grundlage vieler moderner Anwendungen, etwa bei der automatisierten Unkrauterkennung, der Tierüberwachung mittels Kamerasystemen oder der Analyse von Drohnen- und Satellitenbildern. [5]
Natural Language Processing (NLP) bezeichnet den Bereich der Künstlichen Intelligenz, der sich mit der Verarbeitung natürlicher Sprache befasst. Ziel ist es, Computer in die Lage zu versetzen, gesprochene oder geschriebene Sprache zu verstehen, zu analysieren und selbst zu erzeugen. NLP ist somit ein Anwendungsfeld der KI, vergleichbar mit der Bildverarbeitung (Computer Vision), jedoch spezialisiert auf Sprache.
Früher wurden NLP-Systeme häufig regelbasiert oder mit klassischen statistischen Verfahren entwickelt. Heute kommen in vielen Anwendungen Deep-Learning-Modelle zum Einsatz. Große Sprachmodelle (LLMs) stellen dabei eine besonders leistungsfähige Weiterentwicklung innerhalb des NLP-Bereichs dar. [5] [1]
Große Sprachmodelle (Large Language Models, LLMs) sind spezielle Deep-Learning-Modelle, die auf die Verarbeitung und Generierung natürlicher Sprache spezialisiert sind. Sie basieren auf tiefen neuronalen Netzen und werden mit sehr großen Textmengen trainiert. Während des Trainings lernen sie statistische Zusammenhänge zwischen Wörtern, Satzstrukturen und Bedeutungen. Auf dieser Grundlage können sie neue Texte erzeugen, Inhalte zusammenfassen, Fragen beantworten oder Texte analysieren. Große Sprachmodelle sind somit keine eigenständige Kategorie der Künstlichen Intelligenz, sondern eine konkrete Ausprägung von Deep Learning im Bereich der Sprachverarbeitung.
Bekannte Beispiele sind:
Moderne LLMs können zunehmend multimodal arbeiten. Das bedeutet, dass sie neben Text auch Bilder oder andere Datentypen verarbeiten können. [6]
Neben den allgemeinen Grundlagen des Maschinellen Lernens und neuronaler Netze gibt es spezialisierte Anwendungsbereiche der Künstlichen Intelligenz, die für die Landwirtschaft von besonderer Bedeutung sind. Dazu zählen insbesondere Computer Vision (Bildverarbeitung), Natural Language Processing (NLP) und Robotik. Große Sprachmodelle (LLMs) stellen dabei eine moderne Modellklasse dar, die vor allem im Bereich der Sprachverarbeitung eingesetzt wird. Diese Technologien ermöglichen es, komplexe Aufgaben zu automatisieren und datenbasierte Entscheidungen zu treffen.
Computer Vision ist ein Feld der Künstlichen Intelligenz, das Maschinen befähigt, visuelle Informationen aus Bildern und Videos zu "sehen" und zu interpretieren. Dies ähnelt der menschlichen visuellen Wahrnehmung und Analyse. Kernaufgaben von Computer Vision sind die Objekterkennung, Klassifizierung, Verfolgung und Analyse von Merkmalen in digitalen Bildern. [1] [2]
Beispiele in der Landwirtschaft sind unter anderem:
Pflanzenanalyse: Systeme können den Gesundheitszustand von Pflanzen beurteilen, Nährstoffmängel erkennen und Krankheiten oder Schädlingsbefall im Frühstadium identifizieren, oft noch bevor sie für das menschliche Auge sichtbar sind. Dies geschieht durch die Analyse von Blattfarben, -formen oder spezifischen Mustern auf den Pflanzen [7][8][9].
Unkrauterkennung und -bekämpfung: Computer Vision-Systeme können zwischen Nutzpflanzen und Unkräutern unterscheiden. Dies ermöglicht den Einsatz von Präzisionsspritzen oder Robotern, die Herbizide nur gezielt auf Unkräuter auftragen oder sie mechanisch entfernen, was den Einsatz von Chemikalien reduziert [8] [9].
Ernteüberwachung und -vorhersage: Kamerasysteme in Kombination mit KI analysieren das Wachstum und die Entwicklung von Früchten oder Feldfrüchten. Sie können den optimalen Erntezeitpunkt bestimmen und Ertragsprognosen erstellen, indem sie Reifegrade und Fruchtgrößen erfassen [7].
Tierhaltung: In der Tierproduktion wird Computer Vision zur Überwachung des Tierverhaltens, zur Erkennung von Krankheiten oder Lahmheiten und zur individuellen Tieridentifikation eingesetzt. Kamerasysteme können beispielsweise das Fressverhalten, die Aktivität oder die Körperkondition von Tieren kontinuierlich überwachen und Abweichungen melden [10].
Qualitätskontrolle: Bei der Ernte und Weiterverarbeitung können Kamerasysteme Produkte nach Größe, Form, Farbe und Unversehrtheit sortieren und fehlerhafte Ware aussortieren [7].
Natural Language Processing (NLP)
Im landwirtschaftlichen Kontext wird NLP vor allem für wissensbasierte Anwendungen eingesetzt. Dazu zählen die Analyse von Fachliteratur, Markt- und Wetterdaten sowie die Unterstützung bei Dokumentations- und Berichtspflichten. Auch sprachbasierte Assistenzsysteme und digitale Beratungsangebote nutzen NLP-Technologien, um Informationen strukturiert bereitzustellen und Entscheidungsprozesse zu unterstützen. Das erlaubt Landwirten, über sprachbasierte Schnittstellen oder spezialisierte Chatbots direkt auf benötigte Informationen zuzugreifen, sei es für optimale Anbaumethoden für spezifische Bodentypen, effektive Schädlingsbekämpfungsstrategien oder die aktuellen Marktpreise für ihre Produkte. [11]
Roboter sind programmierbare Maschinen, die physische Aufgaben autonom oder teilautonom ausführen können. In Kombination mit KI, insbesondere Computer Vision und Maschinellem Lernen, werden Agrarroboter zunehmend anpassungsfähig und präzise.[1]
Autonome Feldroboter übernehmen Aufgaben wie Aussaat, Düngung oder Unkrautregulierung. Spezialisierte Ernteroboter erkennen reife Früchte und ernten selektiv. In der Tierhaltung sind Melk-, Fütterungs- und Reinigungsroboter bereits weit verbreitet. Sie ermöglichen eine kontinuierliche Überwachung und entlasten Arbeitskräfte.[9]
Der Einsatz Künstlicher Intelligenz eröffnet der Landwirtschaft vielfältige Möglichkeiten zur Effizienzsteigerung und Nachhaltigkeitsverbesserung. Durch die Auswertung großer Datenmengen können betriebliche Entscheidungen fundierter und standortangepasster getroffen werden. Im Pflanzenbau ermöglicht KI eine präzisere Bewässerungs- und Düngestrategie, indem Sensordaten, Wetterinformationen und Bodenparameter kombiniert und analysiert werden. Krankheiten oder Schädlingsbefall können frühzeitig erkannt werden, was gezieltere Maßnahmen und eine Reduktion von Betriebsmitteln erlaubt. Auch die Ertragsprognose kann durch datenbasierte Modelle verbessert werden. In der Tierhaltung unterstützt KI das kontinuierliche Monitoring von Gesundheits- und Verhaltensdaten. Abweichungen können frühzeitig identifiziert und entsprechende Maßnahmen eingeleitet werden. Gleichzeitig tragen automatisierte Systeme zur Arbeitsentlastung und Prozessoptimierung bei. Darüber hinaus bietet KI Potenzial für eine effizientere Betriebsplanung, eine verbesserte Dokumentation sowie eine fundierte Auswertung von Markt- und Produktionsdaten. Insgesamt kann der gezielte Einsatz von KI dazu beitragen, Produktionssysteme ressourcenschonender, wirtschaftlicher und widerstandsfähiger zu gestalten. [9]
Trotz ihres großen Potenzials ist der Einsatz Künstlicher Intelligenz mit verschiedenen Herausforderungen verbunden. Eine zentrale Voraussetzung für leistungsfähige KI-Systeme ist die Verfügbarkeit qualitativ hochwertiger Daten. Die Ergebnisse eines Modells sind unmittelbar von der Qualität, Vollständigkeit und Repräsentativität der zugrunde liegenden Datensätze abhängig. Gerade in der Landwirtschaft sind Daten häufig heterogen, standortabhängig und nicht immer standardisiert, was die Entwicklung robuster Modelle erschweren kann. Hinzu kommt die begrenzte Nachvollziehbarkeit vieler moderner KI-Verfahren. Insbesondere Deep-Learning-Modelle gelten häufig als sogenannte „Black-Box“-Systeme, da ihre internen Entscheidungsprozesse nur schwer transparent gemacht werden können. Dies kann das Vertrauen in automatisierte Entscheidungen beeinträchtigen, insbesondere wenn sie wirtschaftlich oder betrieblich relevante Konsequenzen haben. Auch der Bedarf an technischer Infrastruktur stellt eine Herausforderung dar. Das Training komplexer Modelle erfordert erhebliche Rechenressourcen und entsprechende IT-Strukturen. Zwar sind trainierte Modelle im Einsatz meist effizient, dennoch können begrenzte Internetverfügbarkeit oder fehlende digitale Infrastruktur im ländlichen Raum den flächendeckenden Einsatz erschweren. Darüber hinaus gewinnen Fragen der IT-Sicherheit und des Datenschutzes zunehmend an Bedeutung, da landwirtschaftliche Betriebsdaten sensibel sind und vor unbefugtem Zugriff geschützt werden müssen. Neben technischen Aspekten spielen auch rechtliche und ethische Fragestellungen eine wichtige Rolle. Es gilt zu klären, wer Verantwortung trägt, wenn KI-Systeme fehlerhafte Entscheidungen treffen, und wie Transparenz, Fairness und Nichtdiskriminierung gewährleistet werden können. Gesetzliche Rahmenbedingungen müssen einerseits Innovation ermöglichen und andererseits Missbrauch verhindern. Auch arbeitsorganisatorische Veränderungen sind zu berücksichtigen. Durch Automatisierung können bestimmte Tätigkeiten entfallen oder sich grundlegend verändern, während gleichzeitig neue Anforderungen an digitale Kompetenzen entstehen. Weiterbildung und interdisziplinäre Zusammenarbeit gewinnen daher an Bedeutung. [12]
Künstliche Intelligenz entwickelt sich zu einer wichtigen Schlüsseltechnologie in der Landwirtschaft. Verfahren des Maschinellen Lernens, Deep Learning und spezialisierte Anwendungsfelder wie Computer Vision, NLP und Robotik ermöglichen eine datenbasierte Unterstützung von Pflanzenbau, Tierhaltung und Betriebsmanagement.
Gleichzeitig setzt der erfolgreiche Einsatz qualitativ hochwertige Daten, geeignete Infrastruktur und klare rechtliche Rahmenbedingungen voraus. KI ist kein Selbstzweck, sondern ein Werkzeug, das sinnvoll in betriebliche Prozesse integriert werden muss.
Richtig angewendet kann sie dazu beitragen, landwirtschaftliche Systeme effizienter, ressourcenschonender und zukunftsfähiger zu gestalten.
M. Sc. Maria Scheliga, TH Bingen Experimentierfeld Südwest/DigiBOB